Welcome to the world of Spring Cloud and Kubernetes, where the power of cloud-native applications meets the flexibility of container orchestration. In this tutorial, we will explore the seamless integration of Spring Cloud and Kubernetes, uncovering the secrets to building scalable, resilient, and highly available microservices.
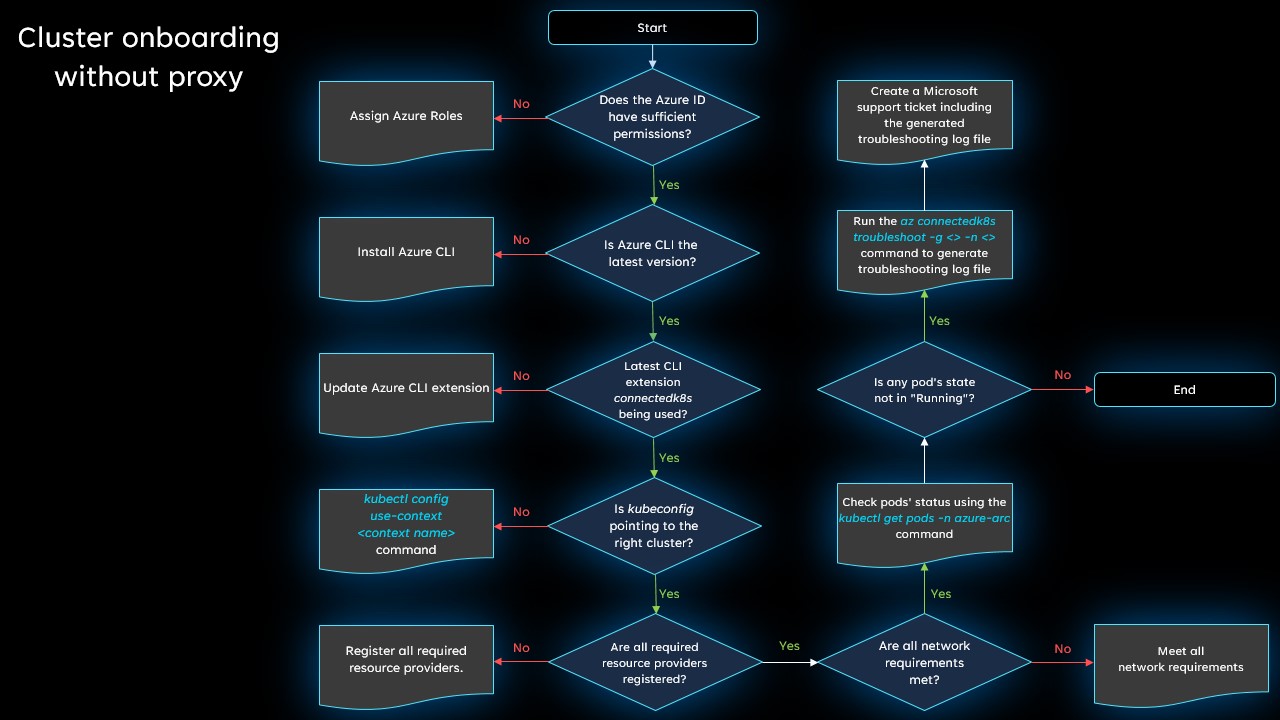
Using a ConfigMap PropertySource
ConfigMap PropertySource is a feature in Spring Cloud Kubernetes that allows you to externalize configuration properties for your applications running in a Kubernetes environment. It allows you to store key-value pairs in a ConfigMap, which can then be accessed by your Spring Boot application.
To use ConfigMap PropertySource, you need to configure your Spring Boot application to read the properties from the ConfigMap. This can be done by adding the `spring-cloud-kubernetes-config` dependency to your project and enabling the ConfigMap PropertySource. Once configured, your application will be able to access the properties just like any other configuration property.
One advantage of using ConfigMap PropertySource is that it allows you to manage your application’s configuration separately from your application code. This makes it easier to manage and update the configuration without having to rebuild and redeploy your application.
To use ConfigMap PropertySource, you need to create a ConfigMap in your Kubernetes cluster. This can be done using the `kubectl` command-line tool or through a YAML configuration file. The ConfigMap should contain the key-value pairs that you want to externalize as configuration properties.
Once the ConfigMap is created, you can mount it as a volume in your application’s pod. This will make the properties available to your application as environment variables. Spring Cloud Kubernetes will automatically detect the presence of the ConfigMap and load the properties into the Spring Environment.
To access the properties in your Spring Boot application, you can use the `@Value` annotation or the `@ConfigurationProperties` annotation. These annotations allow you to inject the properties directly into your beans.
Using ConfigMap PropertySource can greatly simplify the management of configuration properties in a Kubernetes environment. It allows you to externalize your configuration and manage it separately from your application code. This makes it easier to update and manage your application’s configuration without having to redeploy your application.
By using ConfigMap PropertySource, you can take advantage of the powerful features of Spring Cloud Kubernetes while still following best practices for managing configuration in a distributed environment.
Secrets PropertySource
By using Secrets PropertySource, you can store confidential data in Kubernetes Secrets and access them in your Spring Cloud application without exposing them in your source code or configuration files. This ensures that your sensitive information is protected and not visible to unauthorized users.
To use Secrets PropertySource, you need to create a Kubernetes Secret that contains your sensitive data. This can be done using the Kubernetes command-line tool or through YAML configuration files. Once the Secret is created, you can reference it in your Spring Cloud application using the appropriate PropertySource.
By leveraging Secrets PropertySource, you can easily access and manage your secret properties in your Spring Cloud application. This not only enhances the security of your application but also simplifies the management of sensitive information.
To enable Secrets PropertySource in your Spring Cloud application, you need to add the necessary dependencies to your project’s build file, such as Apache Maven or Gradle. Additionally, you need to configure the appropriate PropertySource in your application’s configuration files or by using annotations in your code.
Using Secrets PropertySource in Spring Cloud Kubernetes is considered a best practice for managing sensitive information in your applications. It allows you to securely store and access secrets while following the principles of distributed computing and microservices architecture.
PropertySource Reload
The PropertySource Reload feature in Spring Cloud Kubernetes allows for the dynamic reloading of configuration properties without restarting the application. This is particularly useful in a cloud-native environment where configuration changes may be frequent.
By utilizing the PropertySource Reload feature, developers can make changes to configuration properties without the need to rebuild and redeploy the entire application. This promotes agility and flexibility in managing application configurations.
To enable PropertySource Reload, developers need to add the necessary dependencies to their project’s build file, such as Apache Maven or Gradle. Once the dependencies are added, developers can configure the PropertySource Reload behavior through annotations or configuration files.
One of the key benefits of PropertySource Reload is that it supports different sources of configuration properties, including environment variables, command-line arguments, YAML files, and more. This allows developers to have a centralized and consistent way of managing configuration properties across their applications.
Furthermore, PropertySource Reload integrates seamlessly with other Spring Cloud components such as Spring Boot Actuator, which provides endpoints for monitoring and managing the application’s health, metrics, and other operational aspects.
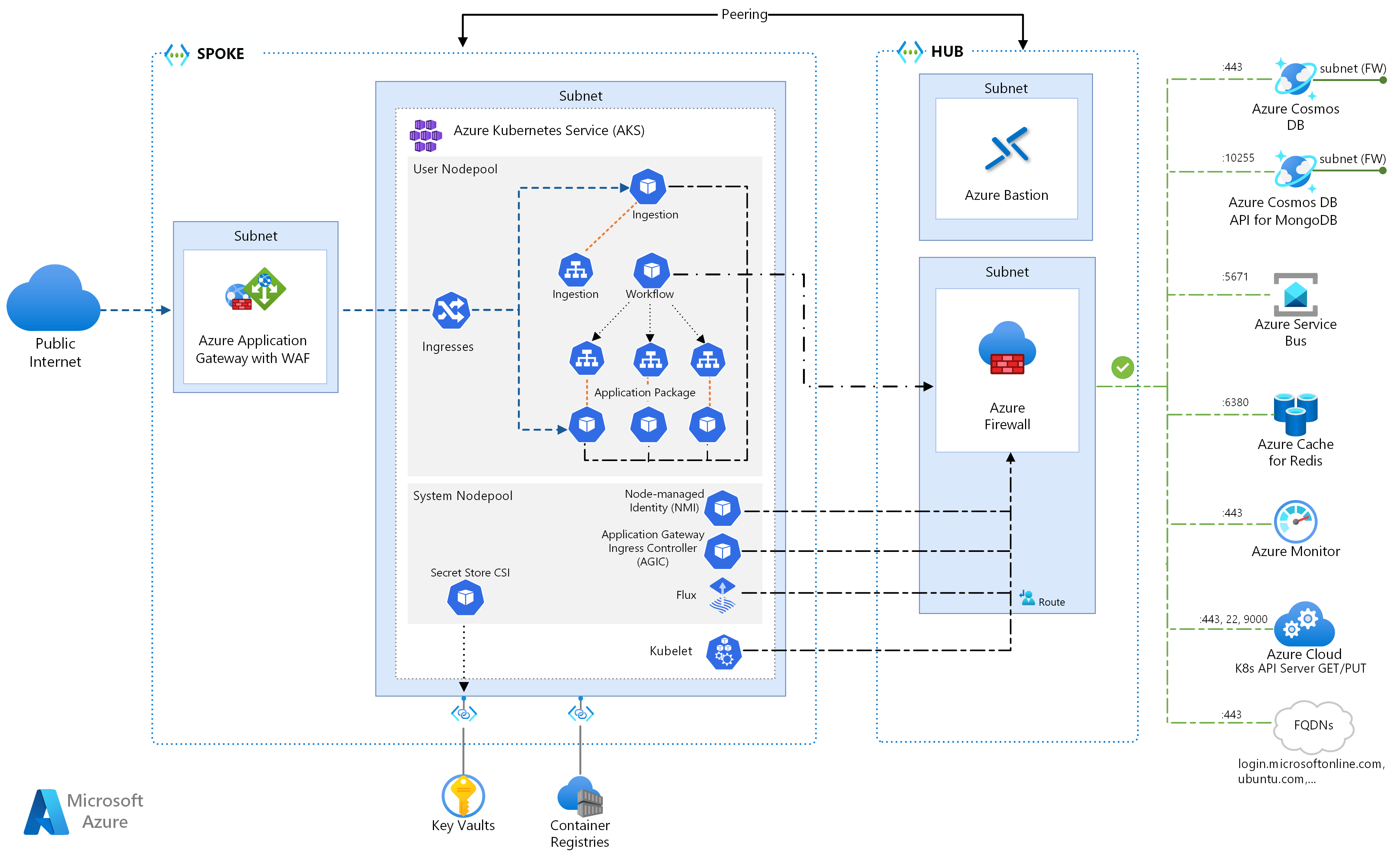
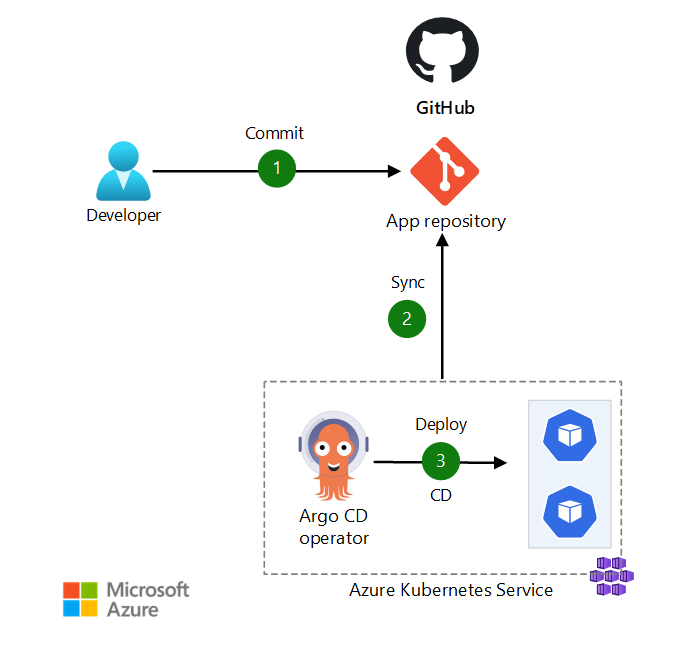
Reference Architecture Environment

In this environment, you can take advantage of the Spring Framework’s extensive features and capabilities to develop robust and high-performing web applications. With its support for RESTful APIs and its integration with Swagger, you can easily design and document your APIs, making it easier for developers to consume them.
Git integration allows for seamless collaboration and version control, ensuring that your codebase is always up-to-date and easily accessible. Environment variables can be used to configure your application at runtime, allowing for flexibility and easy deployment across different environments.
Load balancing is handled by Ribbon, a client-side load balancer that distributes traffic across multiple instances of your application. This ensures that your application can handle high traffic loads and provides a seamless user experience.
Monitoring and managing your application is made easy with the integration of Prometheus and Actuator. These tools provide insights into the health and performance of your application, allowing you to quickly identify and address any issues that may arise.
Service discovery is facilitated by Kubernetes, which automatically registers and discovers services within the cluster. This simplifies the communication between different components of your application and enables seamless scaling and deployment.
Get source code
To get the source code for this Spring Cloud Kubernetes tutorial, you can follow these steps:
1. Open your web browser and navigate to the tutorial’s website.
2. Look for a “Download Source Code” button or link on the tutorial page.
3. Click on the button or link to initiate the download.
4. Depending on your browser settings, you may be prompted to choose a location to save the source code file. Select a location on your computer where you want to save the file.
5. Wait for the download to complete. This may take a few moments depending on the size of the source code.
6. Once the download is finished, navigate to the location where you saved the file.
7. Extract the contents of the downloaded file if it is in a compressed format (e.g., zip or tar).
8. Now you have the source code for the tutorial on your computer. You can use it to follow along with the tutorial or explore the code on your own.
Remember, having access to the source code is valuable for understanding how the tutorial’s concepts are implemented. It allows you to analyze the code, make changes, and learn from practical examples. So make sure to get the source code and leverage it in your learning journey.
If you encounter any issues or have questions about the source code, you can refer to the tutorial’s documentation or seek help from the tutorial’s community or support channels. Happy coding!
Source Code Directory Structure
In Spring Cloud Kubernetes, the source code directory structure typically follows best practices and conventions. It includes different directories for specific purposes, such as source code, configuration files, and resources.
The main directory is often named after the project and contains the core source code files, including Java classes, interfaces, and other related files. This is where the application logic resides and is implemented using the Spring Framework.
Additionally, the source code directory structure may include directories for tests, where unit tests and integration tests are placed to ensure the quality and functionality of the application.
Configuration files, such as application.properties or application.yml, are commonly stored in a separate directory. These files contain properties and settings that configure the behavior of the application.
The resources directory is another important part of the structure. It holds non-code files, such as static resources like HTML, CSS, and JavaScript files, as well as any other files required by the application, like images or XML configuration files.
In a Spring Cloud Kubernetes project, it is common to find a directory dedicated to deployment-related files, such as Dockerfiles and Kubernetes YAML files. These files define how the application should be packaged and deployed in a containerized environment.
Enable Service Discovery Across All Namespaces
By leveraging the power of Spring Cloud Kubernetes, you can easily discover and consume services within your Kubernetes cluster. This eliminates the need to hardcode IP addresses and ports, making your applications more flexible and scalable.
To enable service discovery across all namespaces, you need to follow a few simple steps. First, ensure that you have the necessary dependencies added to your project. Spring Cloud Kubernetes provides a set of libraries and annotations that simplify the integration process.
Next, configure your application to interact with the Kubernetes API server. This can be done by setting the appropriate environment variables or using a Kubernetes configuration file. This step is crucial as it allows your application to access the necessary metadata about services and endpoints.
Once your application is configured, you can start leveraging the power of service discovery. Spring Cloud Kubernetes provides a set of annotations and APIs that allow you to discover services dynamically. You can use these annotations to inject service information into your application code, making it easy to communicate with other services within the cluster.
Additionally, Spring Cloud Kubernetes integrates seamlessly with other Spring Cloud components such as Ribbon for load balancing and Feign for declarative REST clients. This enables you to build robust and scalable microservices architectures using familiar Spring Cloud patterns.
Create Kubernetes namespaces
1. Open your command line interface and navigate to your Kubernetes cluster.
2. Use the command `kubectl create namespace ` to create a new namespace. Replace `` with the desired name for your namespace.
3. You can verify the creation of the namespace by running `kubectl get namespaces` and checking for the newly created namespace in the list.
4. Once the namespace is created, you can deploy your applications and services within it. This helps to organize and isolate different components of your application.
5. Namespaces provide a way to logically separate resources and control access within a Kubernetes cluster. They act as virtual clusters within a physical cluster, allowing different teams or projects to have their own isolated environments.
6. By using namespaces, you can manage resources more effectively, improve security, and simplify the overall management of your Kubernetes cluster.
7. It’s important to follow best practices when creating namespaces. Consider naming conventions that are meaningful and easy to understand for your team. Avoid using generic names that may cause confusion.
8. Namespaces can also be used for resource quota management, allowing you to limit the amount of resources that can be consumed within a namespace.
9. Additionally, namespaces can be used for access control and RBAC (Role-Based Access Control), allowing you to grant specific permissions to different teams or individuals.
10.
Configure MongoDB
1. Add the MongoDB dependency to your project’s Maven or Gradle file.
2. Create a configuration class that sets up the MongoDB connection. Use the **@Configuration** annotation to mark the class as a configuration class.
3. In the configuration class, use the **@Value** annotation to inject the necessary properties for connecting to MongoDB. These properties can be stored in an environment variable or a properties file.
4. Use the **MongoClient** class from the MongoDB Java driver to create a connection to your MongoDB server. Pass in the necessary connection parameters, such as the server URL and authentication credentials.
5. Implement the necessary CRUD (create, read, update, delete) operations using the **MongoTemplate** class from the Spring Data MongoDB library. This class provides convenient methods for interacting with MongoDB.
6. Test your MongoDB configuration by running your Spring Cloud Kubernetes application and verifying that the connection to MongoDB is successful. Use tools like Swagger or a web browser to test the API endpoints that interact with MongoDB.
Remember to follow best practices when configuring MongoDB in a Spring Cloud Kubernetes application. This includes properly securing your MongoDB server, using load balancing techniques for high availability, and optimizing your queries for efficient data retrieval.
Configure Gateway service
To configure the Gateway service in Spring Cloud Kubernetes, follow these steps:
1. Begin by setting up the necessary dependencies in your project. Add the Spring Cloud Gateway and Spring Cloud Kubernetes dependencies to your build file or Maven/Gradle configuration.
2. Next, create a new configuration file for your Gateway service. This file will define the routes and filters for your application. You can use Java configuration or YAML syntax, depending on your preference.
3. Define your routes in the configuration file. Routes determine how requests are forwarded from the Gateway to your backend services. You can specify the URL path, target service, and any additional filters or predicates to apply.
4. Configure load balancing for your routes if necessary. Spring Cloud Gateway supports different load balancing strategies, such as Round Robin or Weighted Response Time. You can specify these strategies using Ribbon, an open-source library for client-side load balancing.
5. Customize the behavior of your Gateway service by adding filters. Filters allow you to modify the request or response, add authentication or authorization, or perform other tasks. Spring Cloud Gateway provides a wide range of built-in filters, such as logging, rate limiting, and circuit breaking.
6. Test your Gateway service locally before deploying it to a Kubernetes cluster. You can use tools like Docker and Kubernetes Minikube to set up a local development environment. This will allow you to verify that your routes and filters are working correctly.
7. Once you are satisfied with your Gateway configuration, deploy it to your Kubernetes cluster. You can use the kubectl command-line tool or the Kubernetes Dashboard for this purpose. Make sure to set the necessary environment variables and resource limits for your Gateway service.
8. Monitor and manage your Gateway service using tools like Prometheus and Grafana. These tools provide visualization and alerting capabilities for metrics collected from your application. You can use them to track the performance and health of your Gateway service.
Gateway Swagger UI
To start using the Gateway Swagger UI, you need to have your Spring Cloud Kubernetes application up and running. Make sure you have all the necessary dependencies and configurations in place.
Once your application is ready, you can access the Gateway Swagger UI by navigating to the appropriate URL. This URL is typically provided by the Spring Cloud Kubernetes framework, and it is usually something like `http://localhost:8080/swagger-ui.html`.
Once you access the Gateway Swagger UI, you will see a list of all the available endpoints in your application. You can click on each endpoint to expand it and see more details about the request and response parameters.
One of the great features of the Gateway Swagger UI is the ability to send test requests directly from the interface. You can enter values for the request parameters and click the “Try it out” button to send a request to your application. The response will be displayed right below the request details, allowing you to quickly test and verify the functionality of your endpoints.
The Gateway Swagger UI also provides documentation for each endpoint, including the request and response schemas, as well as any additional information or constraints. This makes it easy to understand the purpose and behavior of each endpoint, even for developers who are not familiar with the codebase.
In addition to testing and documentation, the Gateway Swagger UI also offers various visualization tools. You can view the overall structure of your application, including the different routes and their corresponding services. This can be helpful for understanding the routing and load balancing mechanisms in your Spring Cloud Kubernetes setup.
Configure Ingress
1. Install and configure the Ingress controller on your Kubernetes cluster. This can be done using a variety of tools such as Nginx, Traefik, or Istio. Make sure to choose the one that best suits your needs.
2. Define the Ingress rules for your application. This involves specifying the hostnames and paths that will be used to route incoming requests to your application. You can also configure TLS termination and load balancing options at this stage.
3. Set up the necessary annotations in your application’s deployment configuration. These annotations provide additional instructions to the Ingress controller, such as specifying which service and port to route traffic to.
4. Deploy your application to the Kubernetes cluster. Make sure that the necessary services and pods are up and running before proceeding.
5. Test the Ingress configuration by sending HTTP requests to the defined hostnames and paths. You should see the requests being routed to your application without any issues.
6. Monitor and troubleshoot the Ingress configuration using tools like Prometheus or Swagger. These tools provide insights into the performance and behavior of your application, allowing you to identify and resolve any issues that may arise.
Testing Ingress
Ingress testing involves verifying that your application can correctly handle incoming requests and route them to the appropriate services. By testing Ingress, you can ensure that your application is properly configured to handle different routing rules and load balancing strategies.
To test Ingress, you can use tools such as Swagger or Postman to send HTTP requests and verify the responses. These tools allow you to easily test various endpoints and parameters to ensure that your application behaves as expected.
Additionally, you can use Git to version control your application code and track changes over time. This can be especially useful when testing Ingress, as it allows you to easily revert to a previous version if any issues arise during testing.
During testing, it is important to consider environment variables and their impact on your application. These variables can be used to configure different settings, such as database connections or API keys, and should be thoroughly tested to ensure they are correctly set and utilized.
Java, being a popular programming language, is commonly used in Spring Cloud Kubernetes applications. Therefore, it is important to thoroughly test your Java code to ensure its functionality and compatibility with the Kubernetes environment.
Testing Ingress is particularly important in cloud computing environments, where applications are often distributed across multiple servers. Load balancing, which involves evenly distributing incoming requests across multiple servers, is a key component of Ingress testing.
In Spring Cloud Kubernetes, Ribbon is a popular load balancing library that can be used to distribute requests. By testing Ingress with Ribbon, you can ensure that your application is properly load balanced and able to handle high volumes of traffic.
Metadata, such as labels and annotations, can also impact Ingress testing. These pieces of information provide additional context and configuration options for your application, and should be thoroughly tested to ensure they are correctly applied.
Open-source software, such as Docker and Prometheus, can greatly assist in Ingress testing. Docker allows you to easily create isolated environments for testing, while Prometheus provides powerful monitoring and visualization capabilities.
When testing Ingress, it is important to follow best practices and adhere to established conventions. This includes properly bootstrapping your application, using the correct Internet Protocol (IP) configurations, and ensuring proper communication between different components.
Bootstrapping the app
When bootstrapping your app in a Spring Cloud Kubernetes environment, there are a few key steps to follow. First, ensure that you have the necessary Linux training to navigate through the process effectively.
To start, you’ll need to set up your environment variables. These variables will define the configuration details for your application, such as the server and port it will run on. This can be done using the command line or by editing a configuration file.
Next, you’ll want to configure your application to work with Kubernetes. This involves adding the necessary dependencies and annotations to your code. Spring Cloud Kubernetes provides a set of tools and libraries to simplify this process.
Once your application is properly configured, you can start leveraging the power of Kubernetes. Kubernetes allows for efficient load balancing and scaling of your application. This is done through the use of Kubernetes services, which distribute incoming requests to multiple instances of your application.
To further enhance your application, consider using tools like Ribbon and Prometheus. Ribbon is a load-balancing library that can be integrated with Spring Cloud Kubernetes to provide even more control over your application’s traffic. Prometheus, on the other hand, is a monitoring and alerting tool that can help you track the performance and health of your application.
Another important aspect of bootstrapping your app is the use of Docker. Docker allows you to package your application and its dependencies into a container, making it easier to deploy and manage. By using Docker, you can ensure that your application runs consistently across different environments.
Finally, it’s important to follow best practices when bootstrapping your app. This includes using a version control repository to track changes, documenting your code and configuration, and following a reference architecture if available.